
With the introduction of SQL Server High Availability options like Availability Groups, Database Mirroring, Clustering etc. the role and the magnitude of SQL Server replication usage have reduced. One of the major reason behind this is because of the complexities involved in maintaining a replication environment. With the being said, Database replication is still relevant in today’s scenarios and have many use cases which cannot be addressed by any other technology without a lot of manual coding. In this post, I am going to talk about SQL Server Replication Interview Questions.
SQL Server Replication Interview Questions
Even though the SQL Server Replication Services (For Example: Merge, Transactional, P2P, Snapshot) are strictly not meant for high availability, the term is used reciprocally. This can confuse you in an interview. It is highly recommended to clarify the interviewee which replication methodology the questions are being asked for. So, let’s get started.
What is the best way to update data between SQL Servers?
There are different types of replication features available in SQL Server, and all of these features have a different use case.
For High Availability and Disaster Recovery:
- Log shipping (Suitable for Reporting and DR)
- Database Mirroring (Real-Time Warm Standby)
- SQL Server Cluster (FCI) (High Availability Only, Not DR)
- SQL Server Always On High Availability (Suitable for Both HA and DR)
- SQL Server Replication (Suitable for DR and Company Branch Sites)
Question: What are the different types of Replication available in SQL Server?
Answer: There are three main types of Replication Services available in SQL Server.
- Snapshot replication – All the three types of replication use a snapshot to initialize Subscribers. The SQL Server Snapshot Agent will always generate a snapshot file, but where it differs is the agent that delivers the files differs depending on the type of replication being used. In a snapshot replication, it takes a snapshot of the published objects and applies it to a subscriber. Snapshot replication completely overwrites the data at the subscriber each time a snapshot is applied. This behavior significantly reduces the use case.
If the data is fairly static or if it’s acceptable to have data out of sync between replication intervals. Just like Merge Replication, A subscriber does not need an always connected system, so data marked for replication can be applied the next time the subscriber is connected. A good example could be to update a list of items that only changes periodically.

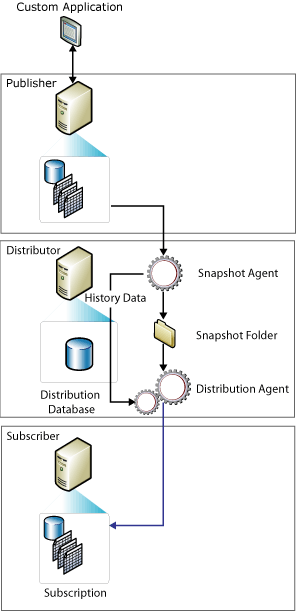
Source: https://technet.microsoft.com/en-us/library/ms151734(v=sql.105).aspx
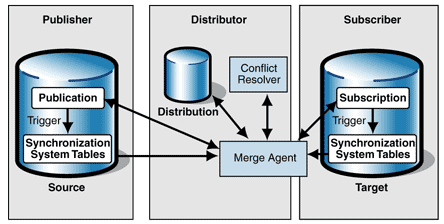
- Merge replication – The Merge Replication setup is a bit more complex since it allows changes to happen at both the publisher and subscriber. All the changes from both the subscribers and the Publishers are merged to keep data consistency and a uniform set of data. The initial synchronization is done by applying snapshot from the snapshot agent. As shown in the image below, when a transaction occurs at the Publisher or Subscriber (which can be disconnected clients), the change is written to change tracking tables. When the subscribers and publishers are connected, the Merge Agent checks these tracking tables and sends the transaction to the distribution database where it gets propagated. The merge agent has a built-in conflict detection and conflict resolution capability for resolving conflicts that occur during data synchronization. An example of using merge replication can be a retail store with many branches offices with POS systems where products may be centrally stored in the inventory database. As the overall inventory is reduced it is propagated to the other stores to keep the databases synchronized.

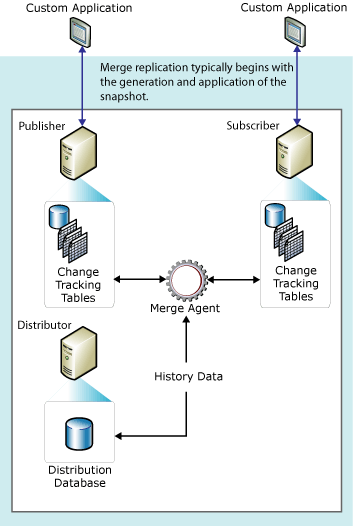
Source: https://technet.microsoft.com/en-us/library/ms151329(v=sql.105).aspx
- Transactional replication – In Transactional, the replication process is implemented by the SQL Server Snapshot Agent, Log Reader Agent, and Distribution Agent. During the initialization process, the Snapshot Agent prepares snapshot files containing schema and data of published tables and database objects, stores the files in the snapshot folder, and records synchronization jobs in the distribution database on the Distributor server. This requires a continuous network connection as it replicates each transaction for the article being published. For the initial setup, a snapshot of the publisher or a backup is taken and applied to the subscriber to synchronize the data. See the image below for a better understanding of the process workflow. After that, when a transaction is written to the transaction log, the Log Reader Agent reads it from the transaction log and writes it to the distribution database and then to the subscriber. Only committed transactions are replicated which ensures data consistency. Transactional replication is widely applied where high latency is not allowed, such as OLTP systems where Availability Groups are a better option. If you need real-time updates of cash or stocks, this is not the ideal solution.

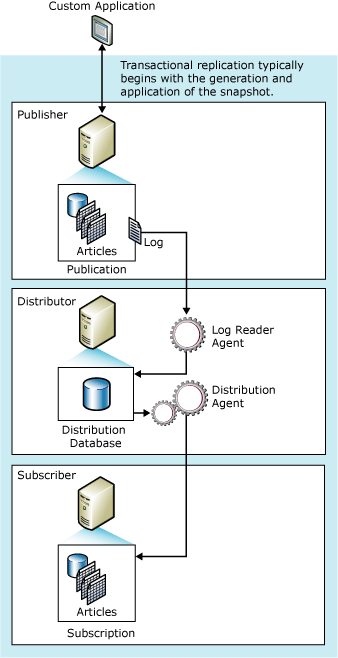
Source: https://technet.microsoft.com/en-us/library/ms151706(v=sql.105).aspx
Transactional Replication has a sub-type of replication, known as Peer to Peer replication which is only available in the Enterprise Edition.
In a Peer-to-peer replication, all the servers act both as a distributor, as well as subscribers. It provides a scale-out and high availability solution by maintaining copies of data across multiple server instances, commonly referred to as nodes. Built on the foundation of transactional replication, peer-to-peer replication propagates transactionally consistent changes in near real-time. This enables applications that require scale-out of reading operations to distribute the reads from clients across multiple nodes. Because data is maintained across the nodes in near real-time, peer-to-peer replication provides data redundancy, which increases the availability of data. P2P replication has a conflict detection system but there is no conflict resolution system which you have in a merge.

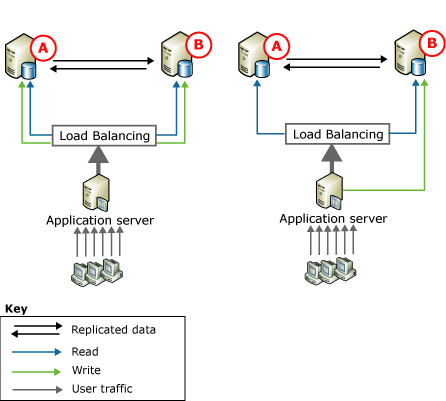
Source: https://technet.microsoft.com/en-us/library/ms151196(v=sql.110).aspx
What is the difference between Push and Pull Subscription?
- Push – In a push subscription, the Publisher pushes data from publisher to the subscriber. Changes can be pushed to all the subscribers on demand, continuously, or on a scheduled basis.
- Pull – In a pull subscription requests for any changes from the Publisher. Used mostly in Merge Replication, this allows the subscriber to pull data as needed. This is useful for disconnected machines which are not always connected to the corporate network. For example, Laptop computers that are not always connected and when they connect they can pull the data to sync the changes.
Question: What are different replication agents and what’s their purpose?
The replication agents are executables which run from the bin folder of the SQL Server Installation directory. The run externally to SQL Server Database engine and runs like an application to connect to SQL Server.
- Snapshot Agent- The Snapshot Agent is required to initialize the replication process and is required by any type of replication method. Based on the published articles, It prepares the schema and the initial bulk copy files of published articles of tables and other SQL objects and stores the snapshot files and records information about synchronization in the distributor database. The Snapshot Agent runs at the Distributor.
- Log Reader Agent – The Log Reader Agent is used with both transactional replication as well as Peer to Peer Replication. It moves transactions marked for replication from the transaction log on the Publisher to the distribution database. For every database published using transactional replication has its own instance of Log Reader Agent that runs on the Distributor and connects to the Publisher. You can run the Distributor on the same computer as the Publisher or on a dedicated system for maximum performance.
- Distribution Agent – The Distribution Agent is used with snapshot replication and transactional replication. It applies the initial snapshot to the Subscriber and moves transactions held in the distribution database to Subscribers. The Distribution Agent runs at either the Distributor for push subscriptions or at the Subscriber for pull subscriptions.
- Merge Agent – The Merge Agent is used with merge replication. After the initial snapshot process is complete, It applies the initial snapshot to the Subscriber and moves and reconciles incremental data changes that occur over time. Each merge subscription has its own Merge Agent that connects to both the Publisher and the Subscriber and updates both based on rules defined. The Merge Agent runs at either the Distributor for push subscriptions or the Subscriber for pull subscriptions.
- Queue Reader Agent – The Queue Reader Agent specifically used with transactional replication with the queued updating option. The agent runs at the Distributor and moves changes made at the Subscriber back to the
Publisher. Unlike the Distribution Agent and the Merge Agent, only one instance of the Queue Reader Agent exists to service all Publishers and publications for a given distribution database.
Question If the queue reader agent fails will the transactional replication completely fails or partially fails?
This will mostly depend on which transactional replication option you choose. If the suspension or disruption occurs while the Queue agent is updating, then it might cause an issue.
How to replicate identity column in merge replication….?
Yes, you can, by using the “NOT FOR REPLICATION CLAUSE” for the column using the identity. What this replication clause will do is tell SQL Server to disable the code that reseeds an identity column when a replication agent is inserting data into an identity column. This preserves all of the identity ranges that you have setup. The drawback to this option is you will not be able to alter a table and once you enable this option.
Does a specific recovery model need to be used for a replicated database?
Replication is not dependent on any particular recovery model. A database can participate in replication whether it is in simple, bulk-logged, or full. However, how data is tracked for replication depends on the type of replication used.
What type of locking occurs during the Snapshot generation?
- Locking depends on the type of replication used:
- In snapshot replication, the snapshot agent locks the object during the entire snapshot generation process.
- In transactional replication, locks are acquired initially for a very brief time and then released. Normal operations on a database can continue after that.
- In merge replication, no locks are acquired during the snapshot generation process.
What options are there to delete rows on the publisher and not on the subscriber?
- One option is to replicate stored procedure execution instead of the actual DELETE command. You can create two different versions of the stored procedures one on the publisher that does the delete and the other on the subscriber that does not do the delete.
- Another option is to not replicate DELETE commands.
Is it possible to run multiple publications and different type of publications from the same distribution database?
Yes, this can be done and there are mostly no restrictions on the number or types of publications that can use the same distribution database. However, you need to use the same database for all Publishers and the same for the Distributor.
How will you monitor replication latency in transactional replication?
You can use Tracer tokens which were introduced with SQL Server 2005 transactional replication as a way to monitor the latency of delivering transactions from the publisher to the distributor and from the distributor to the subscribers.
If I create a publication with one table as an article, and then change the schema of the published table (for example, by adding a column to the table), will the new “Schema” ever be applied at the Subscribers?
Yes. Schema changes to tables must be made by using Transact-SQL or SQL Server Management Objects (SMO). When schema changes are made in SQL Server Management Studio, Management Studio attempts to drop and re-create the table and since you cannot drop a published objects, the schema change will fail.
Is it possible to replicate data from SQL Server to Oracle?

Using Oracle Publisher, you can set up a heterogeneous replication. From SQL Server 2005 onwards, publishing Oracle databases can be directly replicated to SQL Server in the same way as a Standard SQL Server replication setup.
How to monitor replication activity and performance issues? What permissions do you need in order to use replication monitor?
- SQL Server integrates the replication monitor in order to see replication activity and performance. There are other tools and DMV’s to monitor replication performance.
- In order to monitor replication, a user (DBA) must be a member of the sysadmin fixed server role at the Distributor or a member of the replmonitor fixed database role in the distribution database. A system administrator can add any user to the replmonitor role, which allows that user to view replication activity in Replication Monitor only but will not be able to administer replication.
What are the scenarios you will need multiple databases with schema?
How will you plan your replication?
What are Publishers, Distributors, and Subscribers in SQL Server “Replication”?
Publisher: The Publisher is a server that makes data available for replication to other servers. In addition to being the server where you specify which data is to be replicated, the Publisher also detects which data has changed and maintains information about all publications at that site. Usually, any data element that is replicated has a single Publisher, even if it may be updated by several Subscribers or republished by a Subscriber.
Distributor: The Distributor is a server that contains the distribution database and stores metadata, history data, and/or transactions. The Distributor can be a separate server from the Publisher (remote Distributor), or it can be the same server as the Publisher (local Distributor). The role of the Distributor varies depending on which type of replication you implement
Subscribers: Subscribers are servers that receive replicated data. Subscribers subscribe to publications, not to individual articles within a publication, and they subscribe only to the publications that they need, not necessarily all of the publications available on a Publisher.
Can a publication support push and pull at one time?
Yes, A publication can simultaneously support both push and pull subscriptions; however, any given subscriber is restricted to either a push or pull subscription
Can you tell me some of the common replication DMV’s and their use?
- sys.dm_repl_articles – Contains information about each article being published. It returns data from the database being published and returns a row for each object being published in each article.
- sys.dm_repl_schemas – Contains information about each table and column being published. It returns data from the database being published and returns one row for each column in each object being published
- sys.dm_repl_traninfo – Contains information about each transaction in a transactional replication
Additional Questions:
- What are the advantages and disadvantages of using Snapshot replication with use cases?
- What type of data will qualify for “Snapshot replication”?
- What is the actual location where the distributor agent runs?
- Can you explain in detail how exactly “Snapshot Replication” work?
- What is merge replication?
- Explain how does merge replication work?
- What are some of the advantages and disadvantages of Merge replication?
- What is conflict resolution and how does it work in Merge replication?
- What is a transactional replication?
- Explain in detail how transactional replication work?
- What are some of the concerns about data types that needs to be taken into consideration during replication?